27. Transformers
Self-Attention
Modeling sequence without recurrence
Review: Sequence-to-Sequence with Attention
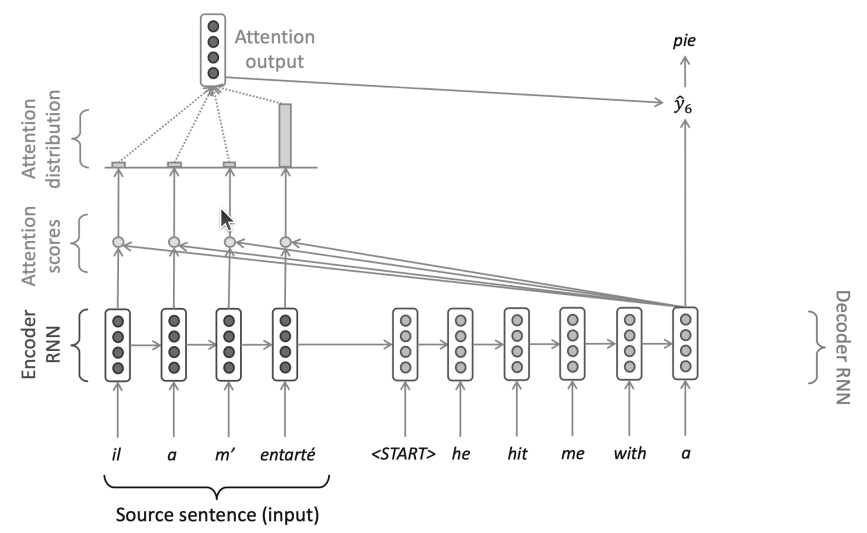
If Not Recurrence, Then What? How About Attention?
- Attention은 각 단어의 표현을 Query로 취급하여 Value 집합의 정보에 접근 및 통합함.
- Decoder에서 Encoder로의 Attention이 아닌, 단일 문장 내에서의 Attention Self-Attention!
- Attention 사용 시, sequence 길이에 따른 병렬화 불가능 연산 수가 증가하지 않음.
- 최대 상호작용 거리: (모든 단어가 모든 레이어에서 상호작용하기 때문).
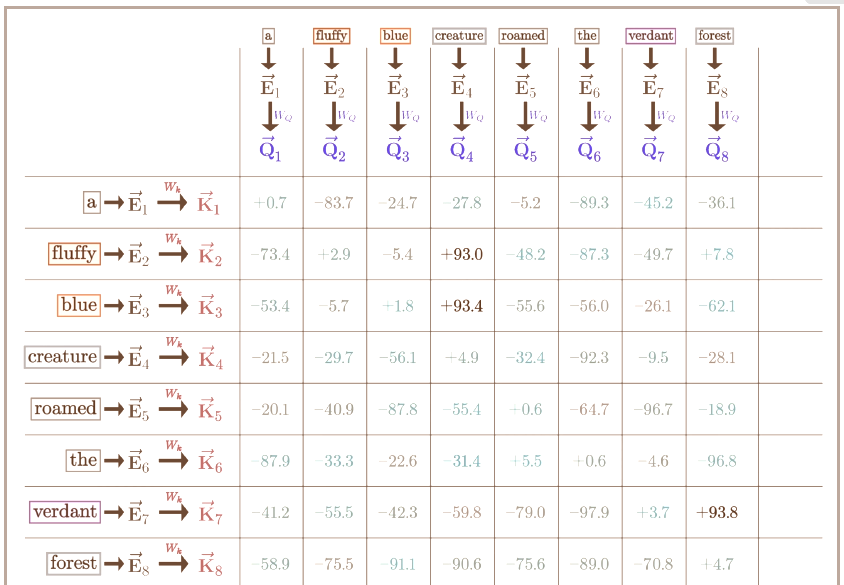
Self-Attention: Keys, Queries, Values from the Same Sequence
- 단어 sequence (어휘 ) 가정
- 예: "Zuko made his uncle tea"
- 각 에 대해 (는 임베딩 행렬)
- 각 단어 임베딩을 가중치 행렬 (각 )로 변환함.
- (Queries), (Keys), (Values).
- Key와 Query 간의 쌍별(pairwise) 유사도 계산 및 로 정규화
- Value의 가중 합으로 각 단어의 출력 계산
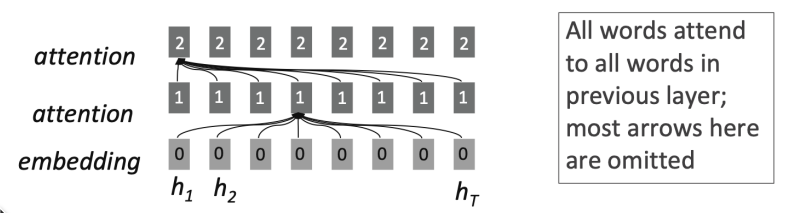
Self-Attention as a Building Block
- 다이어그램과 같이 LSTM 레이어를 쌓는 것처럼 Self-Attention 블록을 쌓음.
- Self-Attention이 순환(Recurrence)의 완전한 대체제가 될 수 있는가?
- No. 몇 가지 문제가 존재하며 이를 살펴보고자 함.
- 첫째, Self-Attention은 집합(Set)에 대한 연산임. 순서(Order)에 대한 내재적 개념이 없음.
Self-Attention은 입력의 순서에 대해서 알지 못함.
Barriers & Solutions for Self-Attention as A Building Block
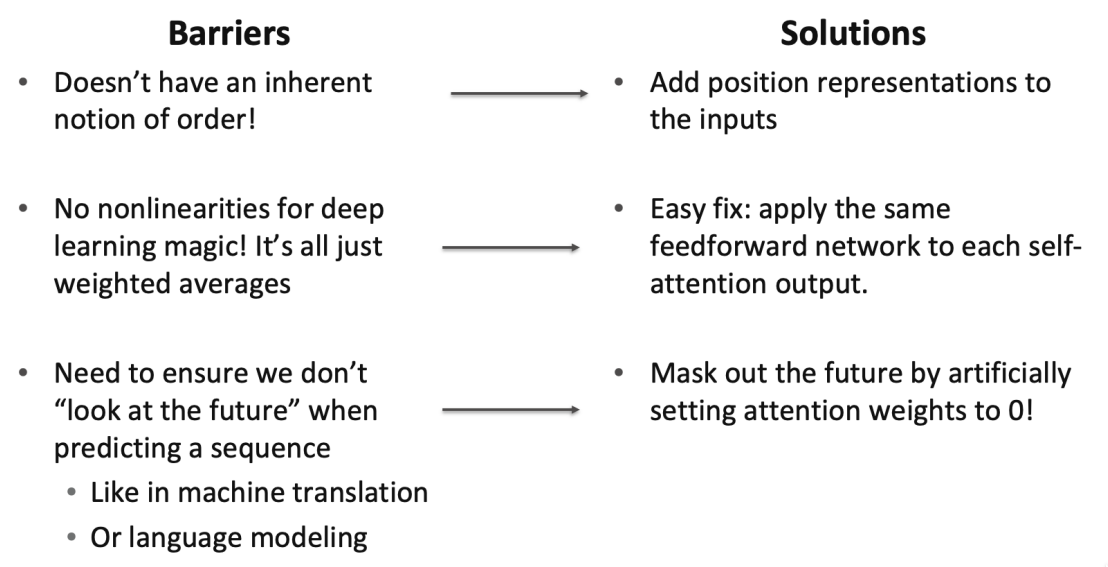
Fixing the First Self-Attention Problem: Sequence Order
- Self-Attention에는 순서 정보가 없으므로 Key, Query, Value에 문장의 순서를 인코딩해야 함.
- 각 sequence 인덱스를 벡터로 표현한다고 가정
- , 은 위치 벡터임.
- 의 구성 방식은 아직 고려하지 않음.
- 이 정보를 Self-Attention 블록에 통합하는 것은 간단함: 입력에 를 더함.
- 는 인덱스 의 단어 임베딩임을 기억
- 위치 정보가 포함된 임베딩
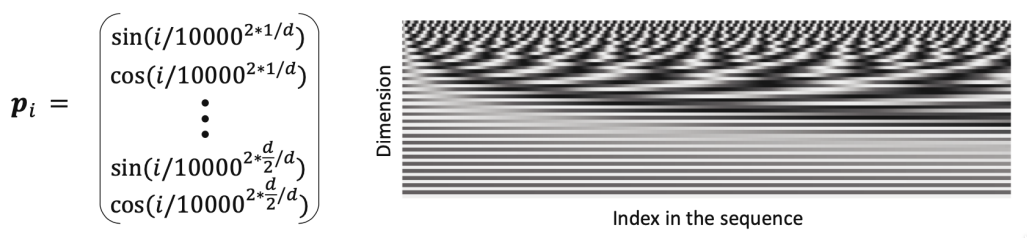
Position Representation Vectors Through Sinusoids
- Sinusoidal position representations(사인파 위치 표현)
- 다양한 주기의 사인 함수를 연결
- 원래의 transformer 논문에서 제안된 방식
- 장점
- 주기성은 "절대 위치"가 중요하지 않을 수 있음을 시사
- 주기가 다시 시작되므로 더 긴 sequence로 extrapolate(외삽) 가능할 수 있음.
- 단점
- Not learnable(학습되지 않음).
- 실제로는 외삽이 잘 작동하지 않음.
Position Representation Vectors Learned from Scratch
- Learned absolute position representations(학습된 절대 위치 표현)
- 모든 를 학습 가능한 파라미터로 설정
- 행렬 을 학습하고 각 를 해당 행렬의 열로 사용
- 대부분의 시스템에서 이 방식을 사용
- 장점: 유연성(Flexibility)
- 각 위치가 데이터에 적합하도록 학습됨.
- 단점: 의 범위를 벗어난 인덱스로는 절대 외삽 불가능
- 때때로 더 유연한 위치 표현을 시도하기도 함
- Relative linear position Attention(상대 선형 위치 어텐션)
- Dependency syntax-based position(의존 구문-기반 위치)
- Rotary position embedding (로터리 위치 임베딩, RoPE)
Adding Non-Linearities in Self-Attention
- Self-Attention에는 elementwise(요소별) 비선형성이 존재하지 않음.
- Self-Attention 레이어를 더 쌓는 것은 단순히 Value 벡터를 re-averaging(재평균화)하는 것에 불과함.
- 간단한 해결책
- 각 출력 벡터를 후처리하기 위해 Feed-Forward Network 추가
Masking the Future in Self-Attention
- Decoder에서 Self-Attention을 사용하려면 미래를 볼 수 없도록 해야 함.
- 매 timestep마다 Key와 Query 집합을 과거 단어만 포함하도록 변경하는 것도 가능
- Parallelization(병렬화)를 가능하게 하기 위해, 미래 단어에 대한 Attention 점수를 로 설정하여 마스킹 처리
Necessities for a Self-Attention Building Block
- Self-Attention
- 방법론의 기초
- Position Representations
- Self-Attention은 입력의 순서를 고려하지 않는 함수이므로 sequence 순서를 명시해야 함.
- Nonlinearities
- Self-Attention 블록의 출력 부분에 위치
- 주로 간단한 Feed-Forward Network로 구현됨.
- Masking
- 미래를 보지 않으면서 연산을 병렬화하기 위함
- 미래의 정보가 과거로 "유출"되는 것을 방지
Transformers
Self-Attention에 기반한 Neural Networks
Transformer
- 오직 Attention 메커니즘으로만 설계된 신경망 아키텍처 (CNN이나 RNN 없이).
"Attention is all you need." (Ashish Vaswani et al., NeurIPS 2017)
- Self-Attention 메커니즘이 핵심에 위치
- 표현의 병렬 계산 가능 Scalability(확장성)
- 본래 Machine Translation(Seq2Seq 아키텍처)을 위해 제안됨.
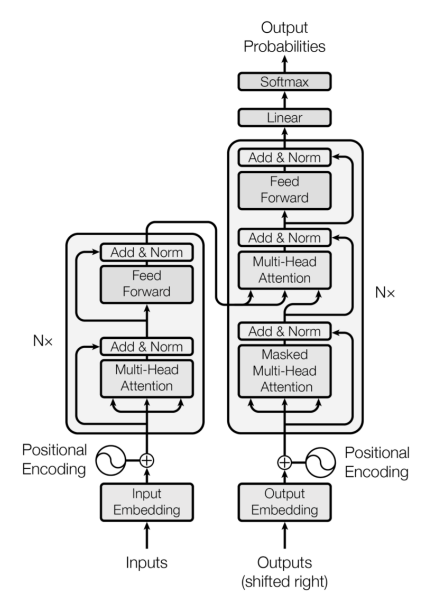
The Transformer Decoder
- Transformer Decoder는 Language Model과 같은 시스템을 구축하는 방식
- 최소한의 Self-Attention 아키텍처와 유사하지만 몇 가지 구성 요소가 추가됨.
- Embedding과 position embedding은 동일
- 다음으로 Self-Attention을 Multi-Head Self-Attention으로 대체할 것
Recall the Self-Attention Hypothetical Example
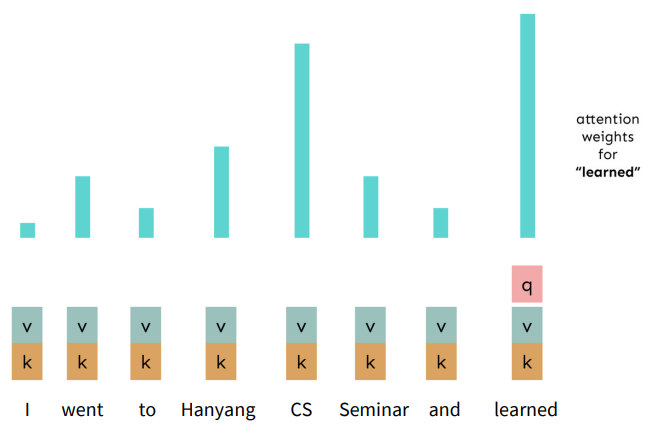
Hypothetical Example of Multi-Head Attention

- Attention head 1은 entity(개체)들에 집중
- Attention head 2는 구문적(문법적)으로 관련된 단어들에 집중
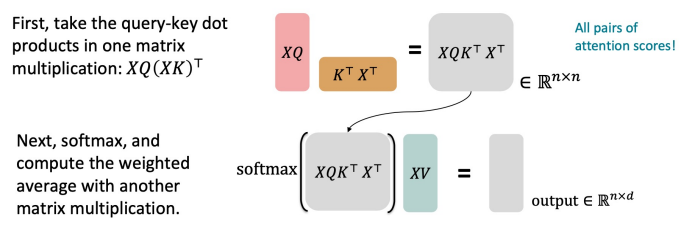
Sequence-Stacked Form of Attention
- 행렬을 통한 Key-Query-Value Attention 계산 방식
- 를 입력 벡터의 concatenation으로 정의
- 출력 정의
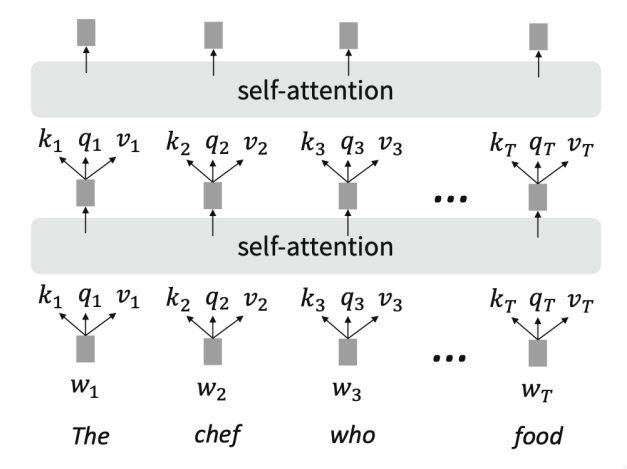
Multi-Headed Attention
- 문장의 여러 위치를 동시에 보고 싶다면?
- 단어 에 대해 Self-Attention은 가 높은 곳을 보지만, 다른 이유로 다른 에 집중해야 할 수도 있음.
- 여러 개의 행렬을 통해 다수의 Attention "Head"를 정의
- (는 Attention Head의 수, 은 1부터 까지).
- 각 Attention Head는 독립적으로 Attention 수행
- 여기서 .
- 그 후 모든 head의 출력을 결합!
- 여기서 .
- 각 head는 서로 다른 것을 보고, Value 벡터를 다르게 구성
Multi-Head Self-Attention is Computationally Efficient
- 개의 Attention head를 계산하더라도 비용이 크게 증가하지 않음.
- 를 계산한 후 로 reshape함 (, 도 동일).
- 그 후 로 transpose.
- 이제 head 축이 batch 축처럼 동작
- 거의 모든 과정이 동일하며, 행렬 크기도 동일
Scaled Dot Product [Vaswani et al., 2017]
- "Scaled Dot Product" Attention은 학습을 도움.
- 차원 가 커지면 벡터 간 내적(Dot product) 값이 커지는 경향이 있음.
- 이로 인해 함수의 입력값이 커져 기울기(Gradient)가 작아짐.
- 해결책
- 기존에 본 Self-Attention 함수 대신, Attention 점수를 로 나누어 차원 수()에 따라 점수가 커지는 것을 방지
The Transformer Decoder
- 두 가지 최적화 trick
- Residual Connections(잔차 연결)
- Layer Normalization(레이어 정규화)
- 대부분의 Transformer 다이어그램에서 이들은 "Add & Norm"으로 함께 표기됨.
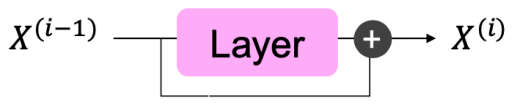
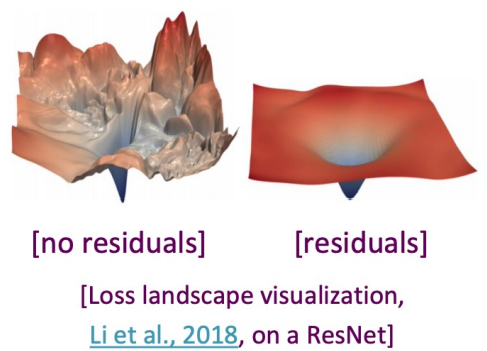
Residual Connections [He et al., 2016]
- Residual connections는 모델 학습을 돕는 trick
- (는 레이어) 대신,
- 로 설정 (이전 레이어로부터의 "잔차"만 학습하면 됨)

- 잔차 연결을 통한 기울기 전파가 원활 (기울기가 1임)
Layer Normalization [Ba et al., 2016]
- Layer normalization은 모델 학습 속도를 높이는 trick
- Idea: 각 레이어 내에서 평균을 0, 표준편차를 1로 정규화하여 은닉 벡터 값의 정보 없는 변동을 줄임.
- LayerNorm의 성공 요인이 기울기 정규화로 추정 [Xu et al., 2019]
- 세부 사항
- 를 모델의 개별 (단어) 벡터라 가정
- : 평균 ().
- : 표준편차 ().
- 와 는 학습된 "Gain"과 "Bias" 파라미터 (생략 가능)
- Layer Normalization 계산 수행
Output = $\frac{x - \mu}{\sigma} \cdot \gamma + \beta
The Transformer Decoder
- Transformer Decoder Block들의 Stack 구조인 Transformer Decoder
- 각 Block 구성 요소
- Self-Attention
- Add & Norm
- Feed-Forward
- Add & Norm
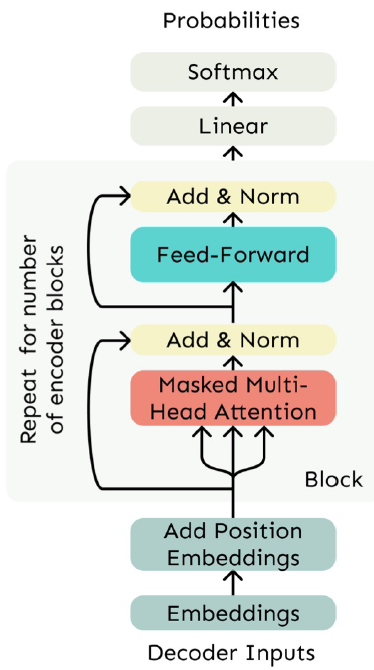
The Transformer Encoder
- Transformer Decoder는 Language Model과 같이 Unidirectional(단방향) 문맥으로 제한됨.
- Bidirectional(양방향) RNN처럼 양방향 문맥을 원한다면?
- 이것이 Transformer Encoder
- 유일한 차이점은 Self-Attention에서 마스킹을 제거한다는 점
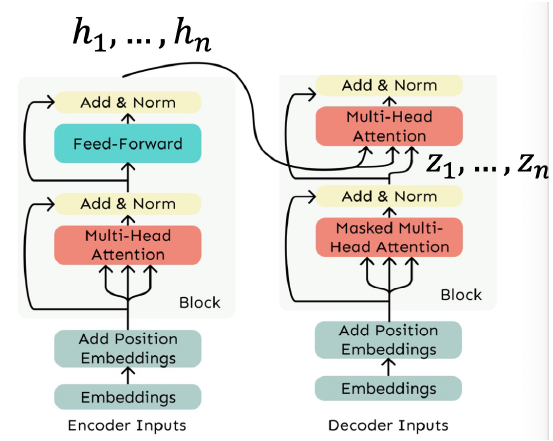
The Transformer Encoder-Decoder
- Machine Translation에서 소스 문장을 양방향 모델로 처리하고 타겟을 단방향 모델로 생성했던 것을 상기
- 이러한 Seq2Seq 형식을 위해 주로 Transformer Encoder-Decoder를 사용
- 일반적인 Transformer Encoder 사용
- Transformer Decoder는 Encoder의 출력에 대해 Cross-Attention을 수행하도록 수정됨.
Cross-Attention
- Self-Attention은 Key, Query, Value가 동일한 소스에서 옴.
- Decoder에서는 이전에 본 것과 더 유사한 형태의 Attention을 가짐.
- 을 Transformer Encoder의 출력 벡터라 함 ().
- 을 Transformer Decoder의 입력 벡터라 함 ().
- Key와 Value는 Encoder에서 추출됨 (메모리 역할).
- Query는 Decoder에서 추출됨.
A Graphical Explanation of Transformers (3Blue 1Brown)
- Transformers (how LLMs work) explained visually
- Attention in transformers, visually explained