작성 2026. 6. 12.·수정 2026. 6. 12.
- Network 내의 각 node는 unit (또는 perceptron)이라 불림
- Unit 계산: (1) 이전 node들로부터의 입력에 대한 weighted sum 계산, (2) output 생성을 위한 비선형 함수 적용
- aj는 unit j의 output, wij는 unit i에서 j로의 weight
- 수식: aj=gj(∑iwijai)≡gj(inj)
- gj: unit j와 연관된 비선형 activation function
- inj: unit j로의 입력에 대한 weighted sum
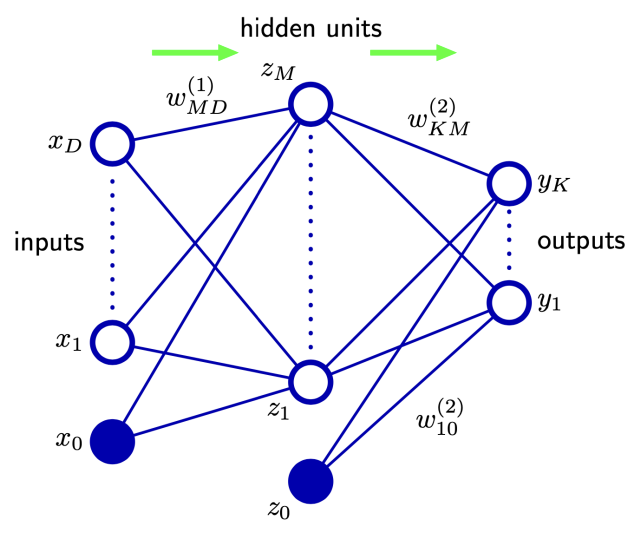
- 입력 변수 x1,…,xD의 M개 linear combinations 구성
- aj=∑i=1Dwji(1)xi+wj0(1), 여기서 j=1,…,M 이고 (1)은 첫 번째 layer
- wji(1): weights, wj0(1): biases
- aj: activations
- 각 activation aj는 미분 가능한 비선형 activation function h(⋅)를 통해 변환
- zj=h(aj), zj는 hidden units
- Hidden units zj는 다시 linear combination 되어 output unit activations ak를 생성
- ak=∑j=1Mwkj(2)zj+wk0(2), 여기서 k=1,…,K 이고 K는 총 output 수
- ak는 적절한 activation function을 통해 network output yk가 됨
- Standard regression: Identity (yk=ak)
- Multiple binary classification: Logistic sigmoid function (yk=σ(ak))
- Multiclass classification: Softmax activation function (yk=exp(ak)/∑lexp(al))
- 전체 network function (예: sigmoid output)
yk(x, w)=σ(j=1∑Mwkj(2)h(i=1∑Dwji(1)xi+wj0(1))+wk0(2))
- w: 모든 weight와 bias parameter를 그룹화한 vector
- 이 과정은 정보의 forward propagation으로 해석 가능
- Neural network model: 입력 x={xi}에서 출력 {yk}로의 비선형 함수
- Bias parameter는 x0=1인 추가 입력 변수 x0를 정의하여 weight parameter에 흡수 가능
aj=i=0∑Dwji(1)xi
- 단순화된 전체 network function (2-layer bias 포함)
yk(x, w)=σ(j=0∑Mwkj(2)h(i=0∑Dwji(1)xi))
- Vector 및 matrices 활용 추가 단순화
y(x, w)=σ(W(2)h(W(1)x))
- Feedforward nets는 일반적으로 fully-connected
- Neural network의 layer 수 계산 용어에 혼란 존재
- 3-layer network: Unit의 layer 수를 세는 방식 (input을 unit으로 취급)
- Single-hidden-layer network: Hidden units의 layer 수를 세는 방식
- Two-layer network: Network 속성을 결정하는 데 중요한 adaptive weights의 layer 수를 세는 방식
- Regression
- Output activation function: Identity (yk=ak)
- Loss (error) function: Sum-of-squares (L2 or squared) error function
E(w)=21n=1∑N∥y(xn,w)−tn∥2
- Binary classification
- Single target variable t (t=1은 C1, t=0은 C2)
- Output activation function: Sigmoid y=σ(a)
- Loss (error) function: Negative log likelihood 또는 cross-entropy error function
E(w)=−n=1∑N{tnlogyn+(1−tn)log(1−yn)}
yn=y(xn,w)
- Multiclass classification
- 각 input은 K개의 상호 배타적인 class 중 하나에 할당
- Target tk∈{0,1}는 1-of-K coding scheme 사용
- Network output 해석: yk(x, w)=P(tk=1∣x)
- Output activation function: Softmax yk=exp(ak)/(∑lexp(al))
- Loss (error) function: Negative log likelihood 또는 cross-entropy error function
E(w)=−n=1∑Nk=1∑Ktnklogyk(xn,w)
- 요약
- 문제 유형에 따라 output unit activation function과 matching error function의 자연스러운 선택 존재
- Entropy
- Random variable의 불확실성 척도
- H(X)=−Ex∼P(X)[logP(x)]=Ex∼P(X)[logP(x)1]
- Kullback-Leibler (KL) Divergence
- 동일한 random variable X에 대한 두 확률 분포 P(X)와 Q(X)가 얼마나 다른지 측정
- DKL(P∥Q)=Ex∼P(X)[logQ(x)P(x)]=Ex∼P(X)[logP(x)−logQ(x)]
- Cross-entropy
- H(P, Q)=−Ex∼P(X)[logQ(x)]=H(X)+DKL(P∥Q)
- Q에 대해 cross-entropy를 최소화하는 것은 KL divergence를 최소화하는 것과 동일

